Research Vignette: Promise and Limitations of Generative Adversarial Nets (GANs)

by Sanjeev Arora, Princeton University and Institute for Advanced Study
 If we are asked to close our eyes and describe an imaginary beach scene, we can usually do so in great detail. Can a machine learn to do something analogous, namely, generate realistic and novel images different from those it has seen before? One expects that some day, machines will be creative and be able to generate even new essays, songs, etc., but for this article, let’s discuss only images. In machine learning, this goal of generating novel images has been formalized as follows. We hypothesize that realistic images are drawn from a probability distribution on the (vast) space of all possible images. Humans appear to be able to imagine novel samples from this vast distribution after having seen a reasonably small number of examples that arose in their personal experience. We would like machines to do the same: sample from the distribution of all realistic images. While this framing of the problem appears anticlimactic – reducing creativity/imagination to the more prosaic act of learning to generate samples from a vast distribution – it is nevertheless a powerful framework that already presents difficult computational hurdles. Many past approaches for solving this distribution learning problem used explicit statistical models, and tended to end in failure (or at best, tepid success) because real life data is just too complicated to capture using simple models.
If we are asked to close our eyes and describe an imaginary beach scene, we can usually do so in great detail. Can a machine learn to do something analogous, namely, generate realistic and novel images different from those it has seen before? One expects that some day, machines will be creative and be able to generate even new essays, songs, etc., but for this article, let’s discuss only images. In machine learning, this goal of generating novel images has been formalized as follows. We hypothesize that realistic images are drawn from a probability distribution on the (vast) space of all possible images. Humans appear to be able to imagine novel samples from this vast distribution after having seen a reasonably small number of examples that arose in their personal experience. We would like machines to do the same: sample from the distribution of all realistic images. While this framing of the problem appears anticlimactic – reducing creativity/imagination to the more prosaic act of learning to generate samples from a vast distribution – it is nevertheless a powerful framework that already presents difficult computational hurdles. Many past approaches for solving this distribution learning problem used explicit statistical models, and tended to end in failure (or at best, tepid success) because real life data is just too complicated to capture using simple models.
This article is about Generative Adversarial Nets (GANs), a proposal by Goodfellow et al. in 20141 to solve this task by harnessing the power of large-scale deep learning (sometimes also called neural net training). Specifically, in the last 5-6 years, deep learning has become very successful at teaching machines to recognize familiar objects in images, in the sense that they can give labels to scenes such as street, tree, person, bicyclist, parked cars with precision approaching or exceeding that of humans. Perhaps this ability can lead naturally to a solution of the sampling problem?
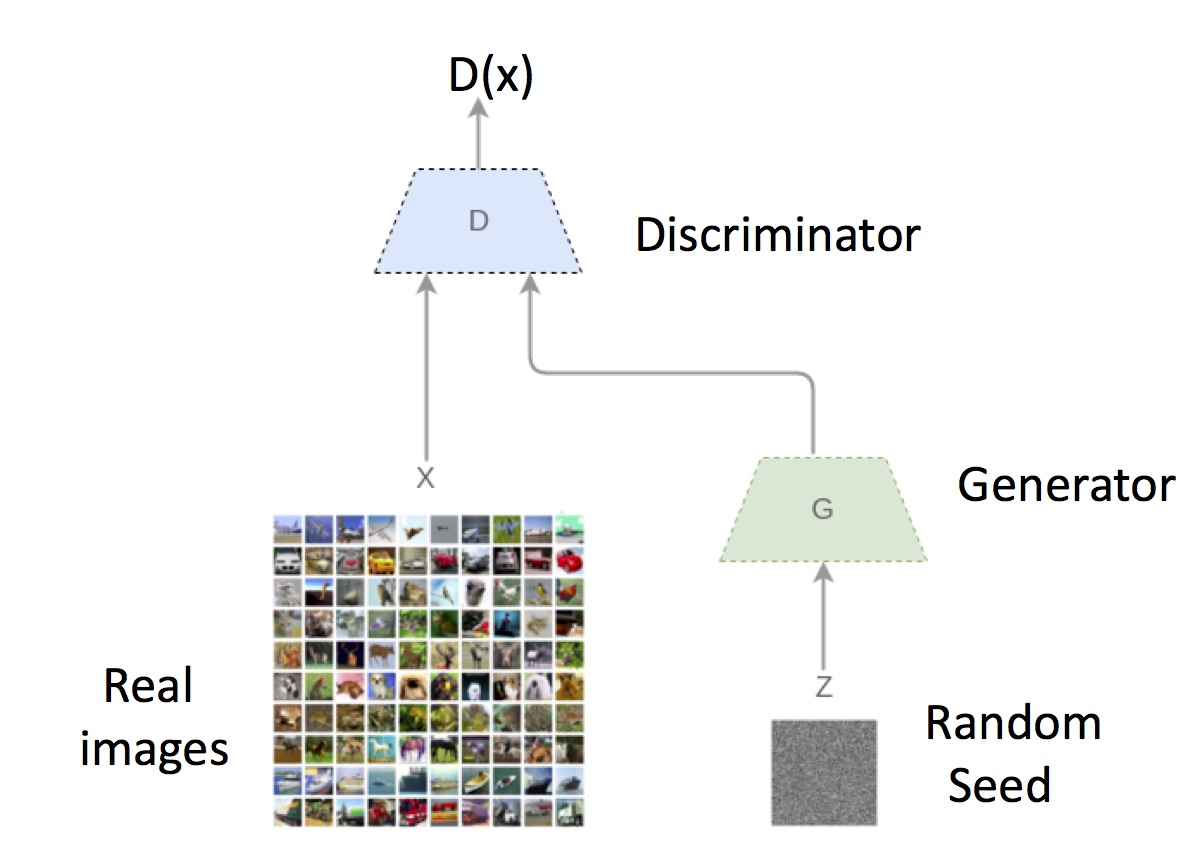
GANs: The Basic Framework
The GAN trains a generator deep net G that converts a random seed z – a Gaussian vector – into an image G(z). Let Psynth be this distribution on synthetic images, which will change and improve during the training.
Main Idea: Since deep nets are good at recognizing images, why not let a deep net be the judge of the outputs of a generative model?
Specifically, train a deep net D (Discriminator) that learns to discriminate between the synthetic distribution and the real distribution in the following sense: D maps images to a value in [0,1], and is trained to produce a high value D(x) when x is a random real image, and a low value when x is drawn from Psynth. (This training is completely analogous to standard deep net training, where a deep net could, for instance, be trained to distinguish between pictures of cats and humans.) While such a discriminator is being trained, the generator deep net is trained alongside to produce outputs that cause the discriminator to output a high value. This objective for the generator is also easily expressed in the standard training procedures for deep nets.
As is now well-known, we lack any theory that proves realistic bounds on the convergence time or sample requirements of such deep net training. But in the case of GANs, there are additional subtleties which future theory must also address: (a) We have implicitly described a 2-person game, where discriminator and generator have opposing objectives. Thus the end goal of training has to be to arrive at an equilibrium, whereby the trained generator is the best response to the trained discriminator and vice versa. At that point, the training stops, since it runs out of any obvious way to improve either. Empirically, such an equilibrium is often hard to attain, and oscillatory behavior may happen. Thus it is an open question whether an equilibrium exists. (Aside for game theory experts: The object being sought is a pure equilibrium, whereas game theory only proves the existence of a mixed equilibrium.) (b) Unlike standard deep learning, where success is validated using performance on a held-out data set, here there is no obvious way to check if the training goal has been achieved; namely that generator learnt to produce a distribution Psynth that is close to the distribution of real-life images. Recall that the goal of GANs is that the generator should learn to produce novel images, instead of just learning to reproduce the images used during the training.
The original paper of Goodfellow et al. in 2014 showed that given enough data, and large enough deep nets, all the above training goals are achieved. Unfortunately, “large enough” in this result means an upper bound that is exponential in the number of pixels in the images. Since the number of pixels is of the order of hundreds of thousands, the result only applies to some hypothetically large nets that will never fit in this universe.
Generalization and Equilibrium: Our paper from spring 2017
My joint work with Ge, Ma, Liang and Zhang (ICML 2017),2 which was written during our stay at the Simons Institute for the Spring 2017 program on Foundations of Machine Learning, shows that an approximate equilibrium exists in the above 2-person game for more realistic values of discriminator size, generator size, and number of training samples. (We require the generator to be slightly larger than the discriminator.) Here, "approximate equilibrium" means that each player’s move is epsilon-approximately optimal against the other player’s move. Furthermore, in this approximate equilibrium, the generator wins, meaning the discriminator has negligible probability of distinguishing real images from the synthetic images.
So, is the mission accomplished? There is only one catch: in this approximate equilibrium, the generator produces a distribution Psynth supported on a small number of images. In other words, this distribution is quite far from the distribution on real images, and yet the discriminator cannot meaningfully distinguish between the two distributions. Thus our theoretical result shows that GANs with finite size discriminators and generators may not do distribution learning very well, even though training may appear to have succeeded!
An empirical test: The Birthday Paradox
Our paper above generated some discussions with colleagues, who suggested that our result should be perhaps viewed as saying "only" that GANs training has ill-behaved solutions, which should not be surprising since so does usual deep net training. However, the two settings are not completely analogous, since in normal deep net training, the bad solutions can be detected by checking performance on held-out data, whereas we can show that held-out data will not help detect the bad solution for GANs.
In subsequent joint work with Yi Zhang3 we put the issue of GANs quality to empirical test. We devised a test for the support size of the generator’s distribution. It uses the famous birthday paradox of elementary probability, which says that in a random sample of 23 humans it is quite likely that two will have the same birthday. (This is deemed paradoxical because the number of possible birthdays is 365.) More generally, the statement is that if a discrete distribution has support N, then a random sample of size about square root of N would be quite likely to contain a duplicate.
In the GAN setting, the distribution is continuous, not discrete. Thus our proposed birthday paradox test for GANs is as follows.
(a) Pick a sample of size S from the generated distribution. (b) Use an automated measure of image similarity to flag the 20 (say) most similar pairs in the sample. (c) Visually inspect the flagged pairs and check for images that a human would consider near-duplicates. (d) Repeat.
If this test reveals with good probability that samples of size S have duplicate images, then suspect that the distribution has support size about S2.
We applied this test to several popular GANs methodologies trained on standard test beds of images. We found that the learned distributions do exhibit low support, roughly consistent with the theory in the first paper.
This empirical test has caused a fair bit of discussion in the deep learning community, which had hitherto not realized the limitations of GANs training. The figure below depicts "Doppelganger" images found in small samples of images from a GAN trained on the "Celebrity Faces" dataset. DCGAN, MIX+ DCGAN, and ALI are three GAN training methods. Each line contains three images; the first two are duplicates found during the birthday paradox test, and the third image (enclosed in the dotted lines) is the closest face we found in the original dataset of images. We find that the Doppelganger image is a novel image, not contained in the original dataset.
Conclusions
It is unclear if GANs properly work at their intended task, which is to learn the underlying distribution. We have presented theory and experiments showing how training can fail in the goal of distribution learning even when the training may superficially appear to succeed. GANs do perform some nontrivial learning, but formalizing what they do is still an open problem.

1 "Generative Adversarial Networks," by Goodfellow, Pouget-Abadie, Mirza, Xu, Warde-Farley, Ozair, Courville, Bengio. NIPS 2014.
2 "Generalization and Equilibrium in Generative Adversarial Nets (GANs)," by Arora, Ge, Liang, Ma, and Zhang. ICML 2017.
3 "Do GANs Actually Learn the Distribution? An Empirical Study," by Arora and Zhang. Arxiv June 2017.
Related Articles
- Letter from the Director, Fall 2017
- In Memoriam: Michael B. Cohen (1992 - 2017)
- In Order Not to Discriminate, We Might Have to Discriminate
- From the Inside: Optimization (1 of 2)
- From the Inside: Optimization (2 of 2)
- Research Vignette: Ramsey Graphs and the Error of Explicit 2-Source Extractors
- Oral History: Russell Impagliazzo in Conversation with Dick Karp
- Simons Institute YouTube Channel Reaches 1 Million Views
- Looking Ahead: Spring 2018