Research Vignette: Ramsey Graphs and the Error of Explicit 2-Source Extractors

by Amnon Ta-Shma, Tel Aviv University
About a century ago, Ramsey proved that in any graph of size N, there exists a monochromatic subset of size ½ log(N), i.e., it is either a clique or an independent set.1 In 1947, Erdős proved there exist graphs with no monochromatic set of size 2log(N).2 Erdős' proof is one of the first applications of the probabilistic method. It is a simple, straightforward counting argument, and like many other counting arguments, it shows almost any graph is good without giving any clue as to any specific such graph. Erdős offered $100 for finding an explicit K-Ramsey graph (a graph where all sets of size K are not monochromatic) for K=O(log N). The best explicit construction until a few years ago was log(K)=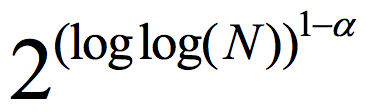 for some constant ∝<1.3
for some constant ∝<1.3
All of this dramatically changed last year. Cohen,4 and independently Chattopadhyay and Zuckerman,5 constructed K-Ramsey graphs with log K=poly loglog(N). Remarkably, Chattopadhyay and Zuckerman explicitly construct the stronger object of a two-source extractor. A function 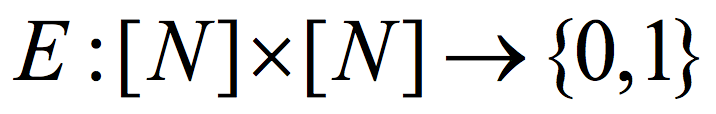 is a (K,ϵ) 2-source extractor if for every two cardinality K subsets
is a (K,ϵ) 2-source extractor if for every two cardinality K subsets 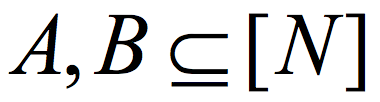 , the distribution E(A,B) (obtained by picking uniformly
, the distribution E(A,B) (obtained by picking uniformly 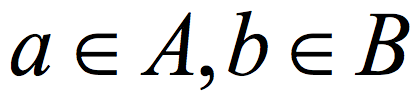 and outputting E(a,b)) is ε close to uniform in the variational distance. Roughly speaking, the Ramsey graph problem is to find a (K, ε) 2-source extractor with any error ε= ε(K) smaller than 1, even allowing error that is exponentially close to 1. In contrast, The CZ construction gives a 2-source extractor with constant error. A 2-source extractor is a basic object of fundamental importance, and the previous best 2-source construction was Bourgain’s extractor, requiring log(K) =
and outputting E(a,b)) is ε close to uniform in the variational distance. Roughly speaking, the Ramsey graph problem is to find a (K, ε) 2-source extractor with any error ε= ε(K) smaller than 1, even allowing error that is exponentially close to 1. In contrast, The CZ construction gives a 2-source extractor with constant error. A 2-source extractor is a basic object of fundamental importance, and the previous best 2-source construction was Bourgain’s extractor, requiring log(K) =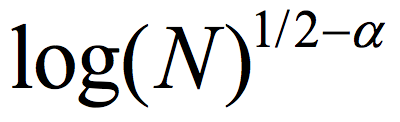 for some small constant α>0. The CZ construction is an exponential improvement over that, requiring only log(K)=polyloglog(N).
for some small constant α>0. The CZ construction is an exponential improvement over that, requiring only log(K)=polyloglog(N).
How does the CZ construction work? Roughly speaking, the first step in the CZ construction is to encode a sample from one source (say 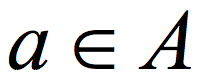 ) with a t non-malleable extractor. I do not want to formally define non-malleability here, but this essentially means that the bits of the encoded string are "almost" t-wise independent, in the sense that except for few "bad" bits, when we look at t bits, they are close to being uniform. The next step in the CZ construction is to use the sample from the second source (
) with a t non-malleable extractor. I do not want to formally define non-malleability here, but this essentially means that the bits of the encoded string are "almost" t-wise independent, in the sense that except for few "bad" bits, when we look at t bits, they are close to being uniform. The next step in the CZ construction is to use the sample from the second source (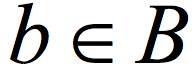 ) to sample a substring of the encoding of a. The sampling is done using an extractor and uses the known relationship between extractors and samplers.6 Finally, a deterministic function, conceptually similar to the Majority function, is applied on the bits of the substring.
) to sample a substring of the encoding of a. The sampling is done using an extractor and uses the known relationship between extractors and samplers.6 Finally, a deterministic function, conceptually similar to the Majority function, is applied on the bits of the substring.
The CZ construction achieves log K=polyloglog(N), where the non-explicit argument of Erdős shows log K=loglog(N)+1 is sufficient. The first bottleneck in the CZ construction, pointed out by Cohen and Schulman,7 is the use of extractors as samplers in the construction. In a recent work, Ben-Aroya, Doron and I showed how to solve this problem using samplers with multiplicative error.8 Furthermore, Dodis et al. showed such samplers are related to low entropy-gap condensers, and Yevgeniy gave a series of talks on such condensers and their applications, mainly in cryptography, during the Spring 2017 Simons Institute program on Pseudorandomness.9 With this, the currently best explicit construction has log K=loglog(N) polylogloglog(N). The extra polylogloglog(N) factor is because current explicit t-non-malleable constructions, even for a constant t, have a suboptimal dependence on ε.
Yet, in my opinion, the most pressing bottleneck is of a completely different nature. The CZ result efficiently constructs a two-source (K,ε) extractor for small values of K, but a large error ε. Specifically, the algorithm computing E(a,b) has running time poly(1/ε), and if we take explicitness to mean running time polynomial in the input length log(N), we can only hope for error which is 1/polylog(N). In contrast, a straightforward probabilistic method argument shows we can hope for an ε which is polynomially small in K. The currently best low-error constructions are Bourgain’s 2-source extractor requiring log 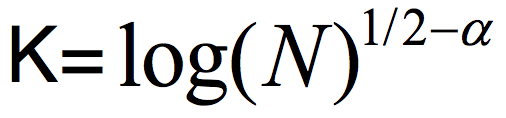 and Raz’ extractor which allows one source to be (almost) arbitrarily weak, but requires the other source to have min-entropy rate above half (the entropy rate is the min-entropy divided by the length of the string). At the Simons Institute program on Pseudorandomness, we were wondering whether the CZ approach that allows both sources to be weak can be somehow modified to give a low-error construction?
and Raz’ extractor which allows one source to be (almost) arbitrarily weak, but requires the other source to have min-entropy rate above half (the entropy rate is the min-entropy divided by the length of the string). At the Simons Institute program on Pseudorandomness, we were wondering whether the CZ approach that allows both sources to be weak can be somehow modified to give a low-error construction?
The CZ analysis reduces the two source extractor problem to a situation where we have many good players who toss truly uniform (or t-wise independent) bits, and few bad players who choose their bits after seeing the coin tosses of the good players, i.e., they are arbitrarily correlated with the good bits. If the number of bad players is small, then with a good probability the bad players do not influence the outcome much. For example, suppose we have a single bad player and we use the majority function. With probability almost 1 when the good players toss their coins, the imbalance between the 1’s and the 0’s is larger than 1, and then the bad player cannot change the result. Still, in such a situation, even a single bad player has at least 1/n influence (and in fact a little bit more). Thus, it seems right that CZ achieve polynomially small error but not less than that, and it seems the CZ approach is doomed to fail for anything better because of the intrinsic nature of the problem.
Thus, this Research Vignette is dedicated to an attempt that Avraham Ben-Aroya, Eshan Chattapodhyay, Dean Doron, Xin Li and I made during the Pseudorandomness program. We adopt the sub-sampling technique of CZ, but we try to completely get rid of all bad players. As before we get two independent samples a and b, we encode a using a t non-malleable extractor, and we use b to choose a substring of the encoding. In CZ, the sub-sample is said to be good if the fraction of bad bits in the subsample is small. This, we saw, is problematic if we shoot for low-error, because even a single bad player has polynomially-small influence. Instead, we would have liked to call the subsample good if none of the bits in the subsample is bad, but it turns out this notion is too strict and no such sampler exists. Our solution is to take a tiny subsample of size at most t, and say the subsample is good if at least one of the bits in the subsample is good. Indeed, in such a case the good bit is independent of the bad bits (because of the t wise independence) and therefore the parity of all bits is close to uniform. We showed that if explicit t non-malleable extractors with good dependence on t exist (and non-explicitly they exist), then using explicit condenser graphs that were built before, one gets low-error two-source extractors.10
The result is not a construction – we do not know how to explicitly build the required t non-malleable extractor. Rather, it is a reduction showing that with such explicit t non-malleable extractors one gets an explicit low-error 2-source extractor. Nevertheless, it shows a new approach to building low-error 2-source extractors. It also exposes a previous bottleneck we have not paid attention to so far. Existing non-malleable constructions mostly focus on the cost (seed length) of extracting uniformity pair-wise independently (over the seeds), and then extend it to t in a somewhat naïve way. Now, we ask about the true cost of achieving t-wise independence. Our work gives an important example where doing better is crucial, and I am sure more examples will follow.
And with that, I would like to conclude and thank the Simons Institute for their generous support of basic research, the incredible staff that made everything so simple, and the many participants in the Pseudrandomness program, for the many stimulating discussions on numerous related (such as t non-malleable extractors, samplers and condensers, low degree unbalanced expanders) and unrelated questions. It may take time, but I believe all those mathematically clean objects will eventually turn into explicit reality!
1 Frank P. Ramsey. On a problem of formal logic. Proceedings of the London Mathematical Society, 30: 264–286, 1930.
2 "Some remarks on the theory of graphs," by Paul Erdős. Bull. Amer. Math. Soc. 53 (4), 1947: 292-294.
3 "2-source dispersers for entropy, and Ramsey graphs beating the Frankl-Wilson construction," by Boaz Barak, Anup Rao, Ronen Shaltiel, and Avi Wigderson. Annals of Mathematics 176(3), 2012: 1483-1543.
4 "Two-source dispersers for polylogarithmic entropy and improved Ramsey graphs," by Gil Cohen. STOC 2016: 278–284.
5 "Explicit two-source extractors and resilient functions," by Eshan Chattopadhyay and David Zuckerman. STOC 2016: 670-683.
6 "Randomness-Optimal Oblivious Sampling," by David Zuckerman. Journal of Random Structures and Algorithms 11(4), 1997: 345-367.
7 "Extractors for near logarithmic min-entropy," by Gil Cohen and Leonard J. Schulman. FOCS 2016: 178-187.
8 "An efficient reduction from two-source to non-malleable extractors: achieving near-logarithmic min-entropy," by Avraham Ben-Aroya, Dean Doron, and Amnon Ta-Shma. STOC 2017: 1185-1194.
9 "Key derivation without entropy waste," by Yevgeniy Dodis, Krzysztof Pietrzak, and Daniel Wichsby. Annual International Conference on the Theory and Applications of Cryptographic Techniques 2014: 93-110
10 "A reduction from efficient non-malleable extractors to low-error two-source extractors with arbitrary constant rate." Avraham Ben-Aroya, Eshan Chattopadhyay, Dean Doron, Xin Li, and Amnon Ta-Shma. ECCC, TR: 17-27.
Related Articles
- Letter from the Director, Fall 2017
- In Memoriam: Michael B. Cohen (1992 - 2017)
- In Order Not to Discriminate, We Might Have to Discriminate
- From the Inside: Optimization (1 of 2)
- From the Inside: Optimization (2 of 2)
- Research Vignette: Promise and Limitations of Generative Adversarial Nets (GANs)
- Oral History: Russell Impagliazzo in Conversation with Dick Karp
- Simons Institute YouTube Channel Reaches 1 Million Views
- Looking Ahead: Spring 2018